I was recently in the position where I wanted to download many articles from a website... This sounded easy enough and from looking online it seems there are bunch of CLI & GUI utilities that can sort this out, to name just a few:
The main issue I kept facing was with authentication. I had tried this sort of thing with wget before but had no luck getting the authentication to work. The same issues occurred when I was trying to use HTTrack (except this time it was issues with the proxy server configuration defaulting to IPv6).
Finally, I decided to go back to wget to hopefully get this download to work...
Setup Link to heading
Before I could start downloading I needed to make sure I could access the site with authorisation via wget (downloading hundreds of "You're Not Authorised to View This Page" pages doesn't sound like my cup of tea). The site I was accessing had both HTTP & form based login, that is, a pop-up that asks for user details and a form in the website to enter the username and password.
The info you'll need is:
- The URL of the login page
- The value name of the username box
- The value of the password box
To identify the names of the form elements in order to pass the correct information to wget. This can be done through a web browser by right-clicking and selecting Inspect (Chrome) / Inspect Element (Firefox) on the username & password box (as demonstrated in the screenshots below). What you need to get is the value name for both fields.
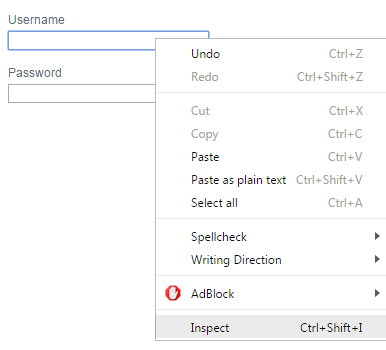
Right click inspect on Chrome

Identifying the value name
Initial Authentication Link to heading
To make sure that the wget command is authenticated for the recursive download we need to obtain & store the cookie. I won't go into depth with an explanation of cookies but I'm sure you've seen many "This site uses cookies" messages online. Basically it's a locally stored authentication token which removes the requirement to login again if you've only recently left & revisited a site.
- Generate
cookies.txtfile containing the cookie data (replaceusername=&password=after--post-datawith the value names collected earlier)
wget --save-cookies cookies.txt --keep-session-cookies --user="My HTTP Username" --password="My HTTP Password" --post-data "username=MyFormUsername&password=MyFormPassword" http://www.awebsite.co.uk/login.php
Make sure to replace My HTTP Username, My HTTP Password, MyFormUsername, MyFormPassword & http://www.awebsite.co.uk/login.php with the info collected earlier!
Preventing Logouts Link to heading
A big issue I hit when running this download was that I'd get a few pages downloaded before getting many pages of "You are unauthorised to view this page". The wget recursion will follow any and all links within the site... including logouts!
This took a bit of trial and error to sort out but eventually I managed to workaround this issue. What you'll need to do is identify the logout links on the page (either through looking around your website with a web browser or by running wget and looking for any URLs with logout in them). The download command is detailed in the next section.
A directory is created with the website name, you'll want to touch the files which have logout in the name so that wget will avoid following those links. Example file tree below:
- awebsite.co.uk
+---- Special:Userlogout
\---- index.php?title-Special:Userlogout
When I tried the above method it allowed me to get further through the download but I eventually started hitting more logout pages. Depending on the site it may be easier to just touch one or two logout files to alleviate the issue however there were hundreds of links on my site so I took a look back at the wget arguments and found the following was able to exclude all pages that include the word logout:
--reject-regex "(.*)logout(.*)"
Downloading Site Link to heading
The command used to download the site will run recursively so you'll have a lot of data to process once the command has exited.
wget --reject-regex "(.*)logout(.*)" -m -c --content-disposition --load-cookies cookies.txt --user="My HTTP Username" --password="My HTTP Password" http://www.awebsite.co.uk/
Output Data Link to heading
With the site I had downloaded I had ended up with the files in XML format. I was only looking for the content of the article so wrote some wrapper scripts to strip out the tags and remove the parts of the file I don't need, I won't disclose this script here as it's very specific to the site & data I was using but some additional tips are below:
- Remove XML tags with sed (replace webpage.html with the filename to run the command on)
sed -e 's/<[^>]*>//g' webpage.html